

A highly scalable, distributed, and robust search engine
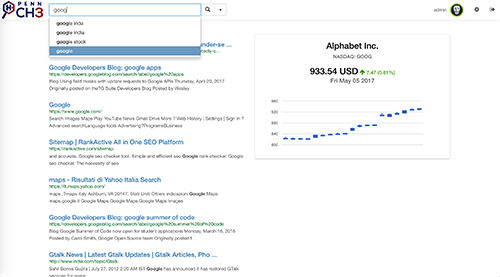
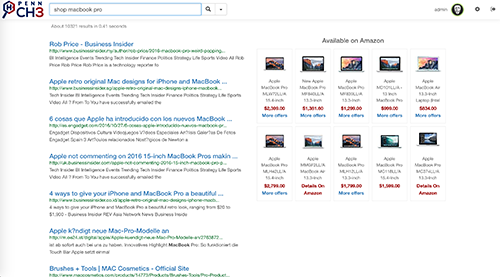
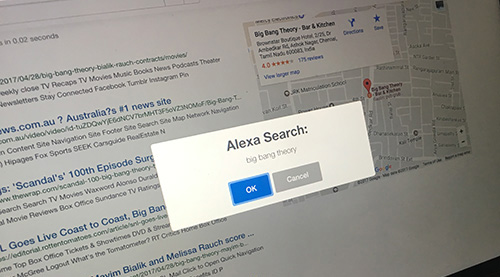
PennCH3's architecture employs a highly scalable distributed crawler which uses locally distributed Berkeley databases to store data while crawling, and lazily saves data on S3. The indexer runs a map reduce job on each file generated by the crawler, thus captures various hits that might be relevant to a query and saves all the data to Amazon S3 via Amazon Elastic MapReduce. After this phase, a standalone multi-threaded application uploads all the generated data to our distributed Berkeley databases, which are also internally parallelized. Web link graph is generated by running a map reduce job on the output of the crawler and the results are used by the page-rank module to compute page-rank scores for non-dangling as well as dangling links by treating them appropriately. The user interface helps to seamlessly integrate the non-trivial algorithms and systems running in the back-end with the user to generate high quality and relevant search results. The search module which is responsible to talk to the user via UI and query the page-rank and indexer modules via REST API's and return results back to the UI. PennCH3 also features a voice-based search via Alexa-enabled devices.
The project was honored with CIS455/555 Google Award.